| Инструкция по настройке плагина TextToday Введение
Данный плагин для TodayScreen позволяет собирать текстовую информацию с различных страниц и отображать ее в одном месте.
Настройка плагина заключается в добавлении шаблона отображения и элементов отображения Элементы
Элементы отображения - эта та текстовая информация, которая выдирается со страничек.
Добавим новый элемент. Для этого, в настройках нажмем кнопку Элементы.
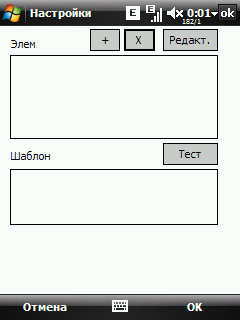 Жмем кнопку "+" и видим окно свойств элемента.
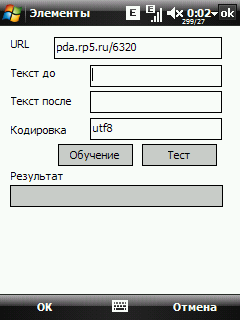 Url - http адрес страницы (можно вводить и без префикса http)
Текст до и текст после - ограничители нужного нам текста
Кодировка - кодировка страницы (пока доступны только utf8, 1251, 1250).
Поля "текст до" и "текст после" можно пока не заполнять, сразу нажимаем кнопку Обучение 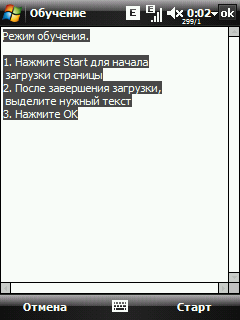 Тут все понятно, читаем текст и жмем Старт. При этом загрузится текстовая версия страницы. 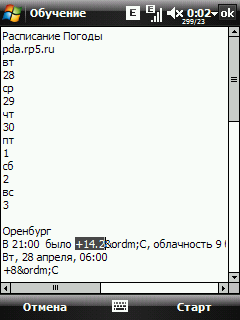 Выделяем нужный текст (в нашем примере это температура) и жмем Ok. Снова возвращаемся на страницу настройки элемента. 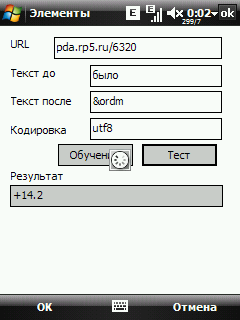 Теперь мы можем отредактировать текст в полях "текст до" и "тест после", убрав оттуда куски изменяющейся информации, если они там есть. Нажав на кнопку Тест, можно проверить правильность выкусывания данных.
Жмем Ok, возвращаемся в настройки шаблона. 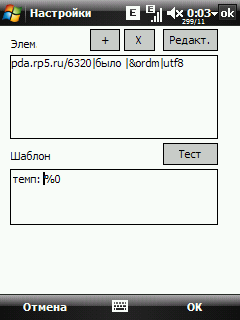
В поле "Шаблон" вводим шаблон информации по следующим правилам:
- текст %0 .. %99 - заменяется на значения вытащенных данных %0 - для первого элемента из списка, %1 для второго и т.д.
- тег
воспринимается как перевод строки
- теги воспринимаются как html теги
- остальной текст копируется как есть.
Выходим из настроек, и в выпадающем меню выбираем пункт Обновить.
Получаем нечто похожее на:
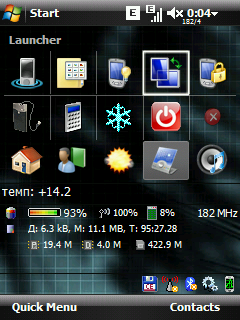 Напоследок маленький хинт. Элементы с одинаковым url следует группировать, тогда для всей группы элементов скачается всего один раз - что дает хорошую экономию трафика. Вот и все! =) Дальнейшее зависит от вашей фантазии.
| 